6月6日,阿里開源通義千問3全新的向量模型系列Qwen3-Embedding(簡稱千問3向量模型)。該模型以千問3為底座��,專門為文本表征��、檢索和排序等核心任務(wù)進行優(yōu)化訓練��,性能較上一版本可提升40%���,在MTEB等權(quán)威專項榜單中超越了谷歌�、OpenAI�、微軟等公司的頂尖模型。
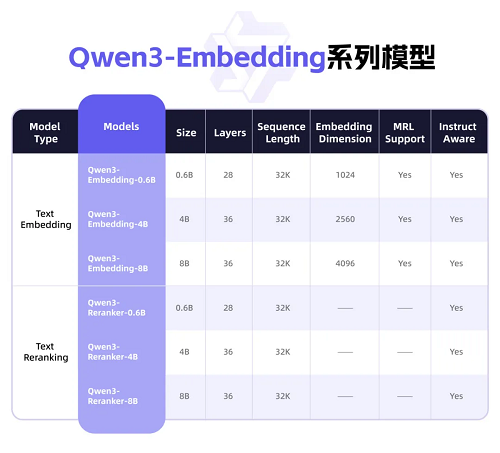
Qwen3-Embedding 系列模型
向量模型像是AI的“翻譯器”�,它可以將文本、圖片等人類可認知的非結(jié)構(gòu)化信息��,映射到機器更易理解的向量空間�����,再基于這些向量實現(xiàn)高效的信息分類��、檢索或排序��。也正因此��,向量模型對于提升AI的語義理解��、信息檢索�����、多模態(tài)融合等核心能力至關(guān)重要?��;谇?模型�����,通義團隊通過對比訓練��、SFT���、模型融合等方法,打造出全新的千問3向量模型�,包含文本嵌入模型 Qwen3-Embedding以及文本排序模型Qwen3-Reranker。
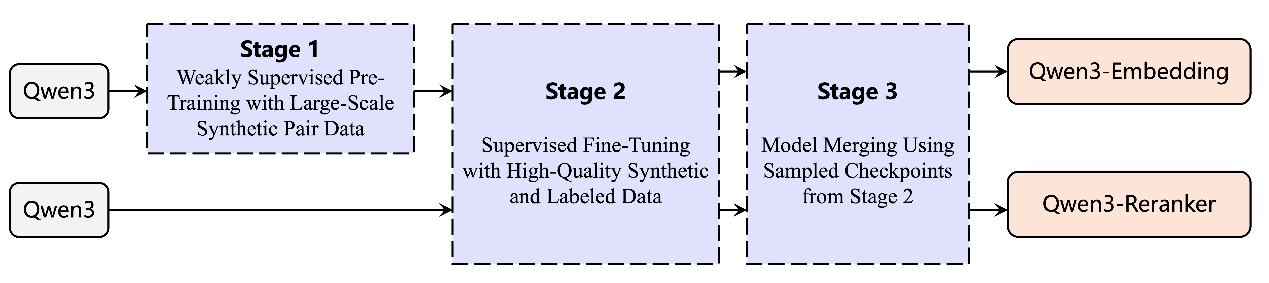
千問3向量模型系列訓練過程圖
相較于上一個版本���,千問3向量模型在文本檢索�、聚類�����、分類等核心任務(wù)上提升最高40%以上的性能�����。同時�,得益于千問3的多語言能力,千問3向量模型系列率先支持超100種語言�����,并涵蓋多種編程語言��,可實現(xiàn)強大的多語言���、跨語言及代碼檢索能力��。
為方便開發(fā)者���,此次有9款千問3向量模型開源,涵蓋0.6B�、4B、8B等不同尺寸及GGUF版本�。開發(fā)者可從中找到最符合需求的模型,自由組合模塊�����,還可自定義向量或指令,實現(xiàn)特定任務(wù)�、語言和場景的深度優(yōu)化。比如��,開發(fā)者可在智能搜索�、推薦系統(tǒng)中采用Qwen3-Embedding作文本向量化,或者在RAG實踐中用Qwen3-Reranker提升最終結(jié)果的相關(guān)性和準確性�����,甚至與視覺理解模型結(jié)合���,探索前沿的跨模態(tài)語義理解��。
目前�,千問3 Embedding和Reranker模型均已在魔搭社區(qū)��、Hugging Face和GitHub等平臺上開源��,開發(fā)者也可直接通過阿里云百煉使用API服務(wù)���。
(責任編輯:蔡文斌)
 晉公網(wǎng)安備 14090202000008號
晉公網(wǎng)安備 14090202000008號 


